我们生活的世界从未像现在这样紧密相连–互联网、移动设备、社交媒体和通信平台在全球范围内的普及,使人们能够接触到比以往任何时候都更多的多语言内容。在这样的背景下,拥有以任何语言按需交流和理解信息的能力变得越来越重要。虽然这种能力一直是科幻小说中的梦想,但人工智能即将把这一愿景变成技术现实。
今天,我们将推出 SeamlessM4T,这是一种基础性的多语言和多任务模式,可跨语音和文本进行无缝翻译和转录。SeamlessM4T 支持
近 100 种语言的自动语音识别
近 100 种输入和输出语言的语音到文本翻译
语音到语音翻译,支持近 100 种输入语言和 35 种(+ 英语)输出语言
支持近 100 种语言的文本到文本翻译
文本到语音翻译,支持近 100 种输入语言和 35 种(+ 英语)输出语言
为了与我们的开放科学理念保持一致,我们将以 CC BY-NC 4.0 的名义公开发布 SeamlessM4T,以便研究人员和开发人员在此基础上开展工作。我们还将发布 SeamlessAlign 的元数据,这是迄今为止最大的开放式多模态翻译数据集,共挖掘了 270,000 小时的语音和文本对齐。通过 SONAR(一套完整的语音和文本句子编码器)和 stopes(我们的多模态数据处理和并行数据挖掘库),我们可以让社区轻松地在自己的单语数据集上进行挖掘。我们的下一代序列建模库 fairseq2 为所有研究进展提供了支持。
建立像《银河系漫游指南》(The Hitchhiker’s Guide to the Galaxy)中虚构的 “巴别鱼”(Babel Fish)那样的通用语言翻译器是一项挑战,因为现有的语音到语音和语音到文本系统只覆盖了世界上一小部分语言。SeamlessM4T 是语音到语音和语音到文本领域的一项重大突破,它解决了语言覆盖面有限和依赖独立系统的难题,将语音到语音的翻译任务分成多个阶段,跨越多个子系统。这些系统可以利用大量数据,通常只在一种模式下表现良好。我们面临的挑战是创建一个统一的多语言模型,它可以完成所有任务。
我们相信,我们今天宣布的工作是在这一道路上迈出的重要一步。我们的单一模式可提供按需翻译,让讲不同语言的人能够更有效地交流。我们大大提高了我们所支持的中低资源语言的性能。这些语言的数字语言足迹较小。我们在英语、西班牙语和德语等高资源语言方面也保持了强劲的性能。SeamlessM4T 能隐式识别源语言,无需单独的语言识别模型。
这项工作的基础是 Meta 和其他公司多年来在开发通用翻译器方面取得的进展。去年,我们发布了 “不遗漏任何语言”(NLLB),这是一个文本到文本的机器翻译模型,支持 200 种语言,并被维基百科整合为其翻译提供商之一。几个月后,我们分享了 “通用语音翻译器 “的演示,这是首个针对福建语(一种没有广泛使用的书写系统的语言)的直接语音到语音翻译系统。通过该系统,我们开发了 SpeechMatrix,这是首个大规模多语言语音到语音翻译数据集,源自 SpeechLASER,是监督表示学习方面的一项突破。今年早些时候,我们还分享了 “大规模多语言语音”(Massively Multilingual Speech)技术,该技术可提供超过1100种语言的自动语音识别、语言识别和语音合成技术。SeamlessM4T借鉴了所有这些项目的研究成果,实现了源自单一模型的多语言和多模态翻译体验,该模型建立在广泛的口语数据源之上,具有最先进的成果。
我们的方法
要建立统一的模型,需要一个轻量级的序列建模工具包,并能与其他现代 PyTorch 生态系统库轻松兼容。我们重新设计了最初的序列建模工具包 fairseq。凭借更高效的建模和数据加载器应用程序接口,fairseq2 为 SeamlessM4T 的建模提供了支持。
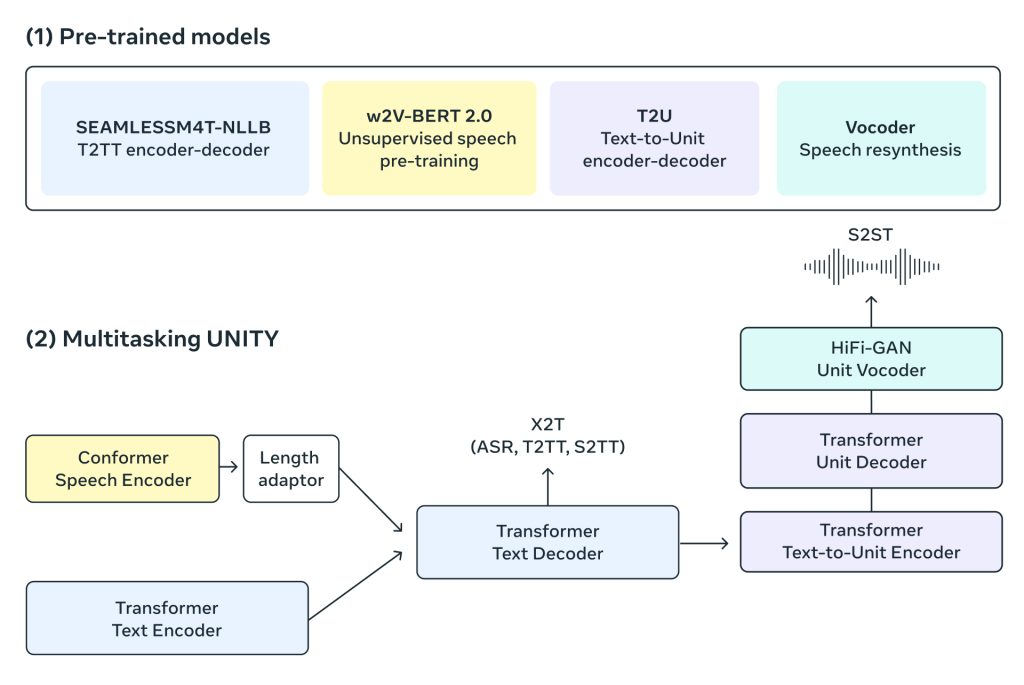
在模型方面,我们使用了多任务 UnitY 模型架构,它能够直接生成翻译文本和语音。这一新架构还支持自动语音识别、文本到文本、文本到语音、语音到文本和语音到语音的翻译,而这些已经是虚构 UnitY 模型的一部分。多任务 UnitY 模型由三个主要的顺序组件组成。文本和语音编码器的任务是识别近 100 种语言的语音输入。然后,文本解码器将意义转换为近 100 种语言的文本,接着,文本到单元模型将意义解码为 36 种语音语言的离散声学单元。自监督编码器、语音到文本、文本到文本翻译组件以及文本到单元模型都经过预先训练,以提高模型的质量和训练稳定性,然后使用多语言 HiFi-GAN 单元声码器将解码后的离散单元转换为语音。
编码器如何处理语音
我们的自监督语音编码器 w2v-BERT 2.0 是 w2v-BERT 的改进版,它提高了训练稳定性和表示质量,并通过分析数百万小时的多语言语音,学会查找语音中的结构和含义。编码器接收音频信号,将其分解成更小的部分,并建立语音的内部表示。由于口语是由许多声音和字符组成的,因此我们使用长度适配器将它们大致映射为实际的单词。
编码器如何处理文本
同样,我们也有一个基于 NLLB 模型的文本编码器。经过训练,它可以理解近 100 种语言的文本,并生成有助于翻译的表述。
生成文本
我们的文本解码器经过训练,可以接收编码后的语音表述或文本表述。这可用于同一语言的任务,如自动语音识别和多语言翻译任务。例如,有人可以用法语说 “bonjour”(你好),而斯瓦希里语的翻译文本可能是 “habari”(哈巴里)。通过多任务训练,我们可以利用强大的文本到文本翻译模型(NLLB)的优势,通过标记级知识提炼来指导我们的语音到文本翻译模型。
生成语音
我们使用声学单元来表示目标方的语音。UnitY 模型中的文本到单元(T2U)组件根据文本输出生成这些离散的语音单元,并在 UnitY 微调之前在 ASR 数据上进行预训练。然后使用多语言 HiFi-GAN 单元声码器将这些离散单元转换为音频波形。
数据缩放
像 SeamlessM4T 这样的数据驱动模型通常得益于大量高质量的端到端数据,即语音到文本和语音到语音数据。仅依靠人工转录和翻译的语音无法应对 100 种语言语音翻译的挑战性任务。我们利用联合嵌入空间中的相似性度量进行文本到文本的挖掘,并在此基础上开展了语音挖掘方面的初步工作,为训练 SeamlessM4T 模型创建了额外的资源。
首先,我们为 200 种语言构建了一个新的大规模多语言和模式文本嵌入空间,命名为 SONAR(句子级 mOdality- 和 laNguage-Agnostic Representations),它在多语言相似性搜索方面大大优于 LASER3 或 LaBSE 等现有方法。然后,我们采用师生方法将这一嵌入空间扩展到语音模态,目前已涵盖 36 种语言。挖掘的数据来自公开的网络数据(数百亿句子)和语音(400 万小时)资源库。我们总共自动对齐了超过 443,000 小时的语音和文本,并创建了约 29,000 小时的语音对语音对齐。该语料库被称为 SeamlessAlign,是迄今为止总量和语言覆盖范围最大的开放式语音/语音和语音/文本并行语料库。
研究结果
对于这些任务和语言,SeamlessM4T 在近 100 种语言中取得了最先进的结果,并在自动语音识别、语音到文本、语音到语音、文本到语音和文本到文本翻译等多任务支持中实现了所有这些功能。我们还大大提高了所支持的中低资源语言的性能,并保持了高资源语言的强劲性能。
为了在不依赖基于文本的指标的情况下更准确地评估系统,我们在 BLASER 2.0 中扩展了我们的无文本指标,该指标现在可以在语音和文本单元之间进行评估,其准确性与前代指标类似。在进行鲁棒性测试时,与当前最先进的模型相比,我们的系统在语音到文本任务中对背景噪音和说话者变化的处理能力更强(平均分别提高了 37% 和 48%)。
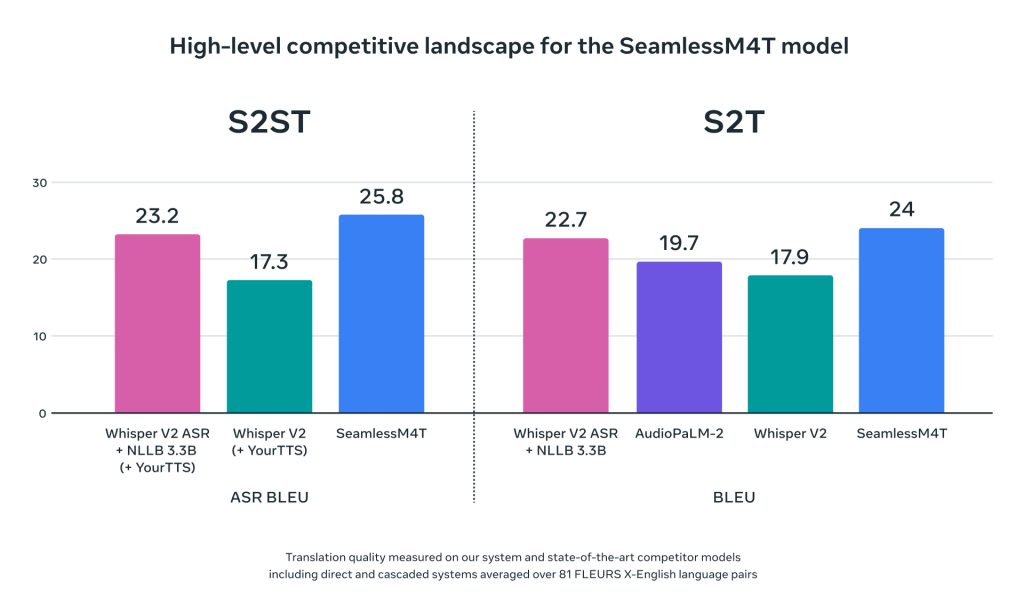
SeamlessM4T 的表现也优于之前的一流竞争对手。
我们如何负责任地构建 SeamlessM4T
翻译系统的准确性非常重要。与所有人工智能系统一样,人工智能模型存在固有的风险,可能会误译一个人想说的话,或者产生有毒或不准确的输出。
在 Meta,我们的人工智能研发遵循一个负责任的框架,该框架以我们的 “负责任的人工智能 “五大支柱为指导。根据我们对负责任人工智能的承诺,我们对毒性和偏差进行了研究,以帮助我们了解模型的哪些方面可能是敏感的。在毒性方面,我们将高度多语言毒性分类器扩展到语音,以帮助识别语音输入和输出中的毒性词语。我们过滤了训练数据中不平衡的毒性。如果输入或输出包含不同数量的毒性,我们就会删除该训练对。
我们今天发布的演示展示了 SeamlessM4T 的功能,也是研究的重要组成部分。我们在演示中同时检测输入和输出中的毒性。如果只在输出中检测到毒性,则表示毒性已被添加。在这种情况下,我们会发出警告,并不显示输出结果。将我们的模型与最先进的模型进行比较时,我们在语音到语音和语音到文本的翻译中都大大减少了附加毒性。
性别偏见,即结果不公平地偏向某一性别,有时默认为性别刻板印象,是我们开始大规模评估语言的另一个领域。通过将我们之前设计的多语言整体偏见数据集扩展到语音领域,我们现在能够量化数十种语音翻译方向的性别偏见。
我们围绕安全和保障开展的工作仍在继续。我们将继续在这一领域开展研究并采取行动,以不断改进 SeamlessM4T,并减少我们在模型中发现的任何毒性情况。
提供我们的技术
凭借最先进的成果,我们相信 SeamlessM4T 是人工智能界在探索创建通用多任务系统方面的一个重要突破。为了与我们的开放科学方法保持一致,我们很高兴能公开分享我们的模型,让研究人员和开发人员能够在此技术的基础上进行开发。
我们一直在努力打造人工智能驱动的技术,帮助人们跨语言沟通,而这只是我们努力的最新一步。未来,我们希望探索这一基础模型如何实现新的交流能力–最终让我们更接近一个人人都能被理解的世界。