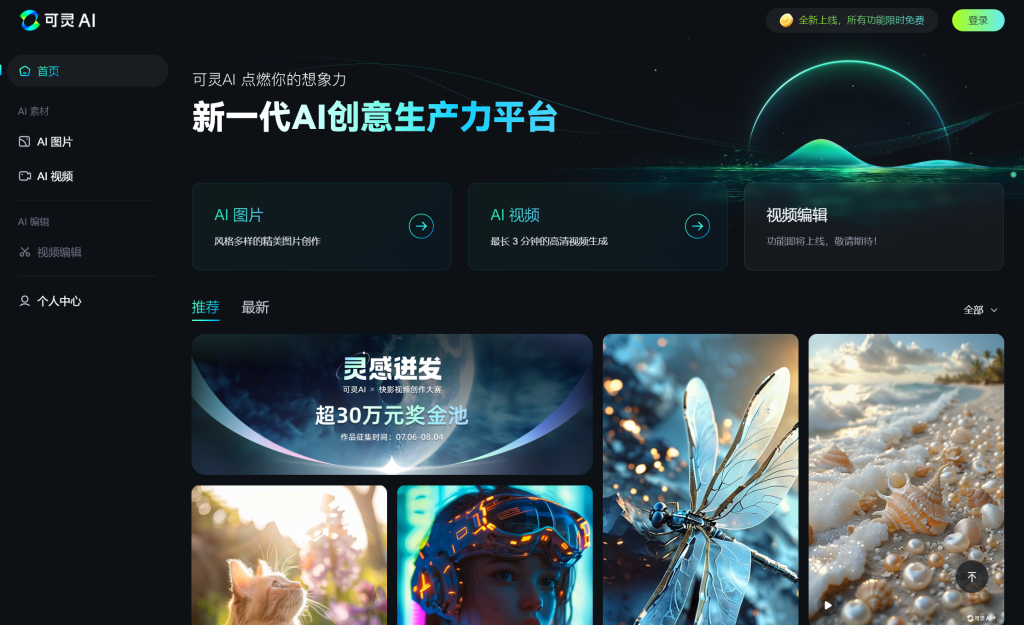
安是加州大学旧金山分校爱德华-张(Edward Chang)领导的一项语言神经义肢研究的参与者,她的大脑信号被连接到电脑上,电脑将她的大脑信号转化为一个化身的语言和面部动作。左为加州大学旧金山分校临床研究协调员马克斯-多尔蒂。(照片由诺亚-伯杰拍摄)
新型大脑植入物帮助瘫痪妇女使用数字化身说话
伯克利的工程师们解释了人工智能的进步如何帮助恢复自然交流
2023 年 8 月 23 日 作者:马尼-埃勒里
新出现的语音神经义肢可能会为因瘫痪或疾病而无法说话的人提供一种交流方式,但快速、高性能的解码尚未得到证实。现在,加州大学旧金山分校和加州大学伯克利分校研究人员的变革性新工作表明,利用人工智能的最新进展,可以实现更自然的语音解码。
在加州大学旧金山分校神经外科医生爱德华-张(Edward Chang)的领导下,研究人员开发出一种可植入的人工智能驱动设备,首次将大脑信号转化为调制语音和面部表情。结果,一名因中风而丧失说话能力的妇女能够通过一个会说话的数字化身说话和表达情感。研究人员在今天(8月23日星期三)发表在《自然》杂志上的一项研究中介绍了他们的工作。
这项研究的共同作者、加州大学伯克利分校电子工程与计算机科学系助理教授戈帕拉-阿努曼奇帕利(Gopala Anumanchipalli)和博士生、共同第一作者凯洛-利特尔约翰(Kaylo Littlejohn)与伯克利工程学系讨论了这项突破性研究。为了篇幅和清晰起见,以下问答经过了编辑。
这项研究在许多方面都具有开创性。您的角色是什么,您的目标是什么?

戈帕拉 这个项目背后有着长达十年的历史。当我还是爱德华-张实验室的博士后时,我们的任务是了解流利语言产生的大脑功能,并将这些神经科学研究成果转化为工程解决方案,以帮助那些完全瘫痪的交流障碍者。我们在与癫痫患者合作时,研究了通过大脑活动记录进行语音合成的方法。但这些人都是有其他能力的演讲者。这项原理验证工作于 2019 年发表在《自然》杂志上。因此,我们隐约觉得可以读出大脑。然后,我们认为应该尝试用它来帮助瘫痪病人,这就是 BRAVO(BCI 恢复手臂和声音)临床试验的重点。
该试验使用了一种名为 “语音神经假体 “的新设备,取得了成功,表明我们可以从大脑活动中解码出完整的单词。随后,我们又进行了另一项研究,成功解码了 1,000 多个单词,创建了一个拼写界面。参与者可以说出任何北约代码单词,如 Alpha、Bravo、Charlie,并将其转录下来。我们改进了用于解码语音的机器学习模型,特别是通过使用具有明确语音和语言模型的解码器,将这些代码单词转化为流畅的句子,就像 Siri 识别你的声音一样。
在这个项目中,我们的目标是增加词汇量和准确性,但最重要的是,我们的目标不仅仅是解码拼写。我们希望直接使用口语,因为这是我们的交流方式,也是我们最自然的学习方式。
化身背后的动机是帮助参与者感受到自己的存在,看到一个相似的人,然后控制这个相似的人。因此,我们希望为此提供一种多模态交流体验。
你们是如何将大脑信号转化为语言和表情的?你们在工程设计中遇到了哪些挑战?

凯洛:由于瘫痪病人不能说话,我们没有他们想说的话作为映射的 “地面实况”。因此,我们采用了一种名为 CTC loss 的机器学习优化技术,它能让我们将大脑信号映射到离散单元,而无需 “地面实况 “音频。然后,我们将预测的离散单元合成为语音。语音的离散单元对音高和音调等方面进行编码,然后进行合成,以创建更接近自然语音的音频。正是这些语气和语调的变化,在语音中传达了许多实际话语之外的含义。
在文本方面,肖恩-梅茨格(Sean Metzger,共同第一作者,加州大学伯克利分校和加州大学旧金山分校生物工程联合项目的博士生)将单词分解为音素。
我们还将其进一步扩展到语音和面部表情等更自然的交流模式,其中的离散单元是发音手势,如嘴部的特定动作。我们可以通过大脑活动预测手势,然后将其转化为嘴部动作。
在面部动画方面,我们与 Speech Graphics 合作,将手势和语音制作成数字头像动画。
戈帕拉 为了强调凯洛的观点,我们使用了所有现有的人工智能技术来模拟特定句子的有效输出。我们使用 Siri、谷歌助手和 Alexa 使用的大型语音模型中的语音数据来实现这一目标。因此,我们对口语的有效代表单元序列有了一个概念。这可能就是大脑信号所对应的内容。例如,参与者正在朗读句子,然后我们使用这些数据的模拟对:输入是她的大脑信号,输出是这些大型口语模型预测的离散代码序列。
此外,我们还使用了大约 20 年前她在婚礼上发表演讲的视频录像,从而对参与者的声音进行了个性化处理。我们根据她的声音对离散代码进行了微调。一旦我们模拟出这种配对排列,我们就会使用凯洛提到的序列排列方法,即 CTC 损失法。
这个多模态语音假肢的一个重要部分是虚拟化身。在使用这种视觉组件时,有什么特别的考虑或挑战吗?
凯洛 使用这种头像的主要动机是为语音和文本解码提供补充输出。头像可以用来表达很多非语音表达。例如,在论文中,我们展示了我们可以解码参与者微笑、皱眉或做出惊讶表情的能力–而且是在从低到高的不同强度下。此外,我们还展示了对非语言发音手势的解码能力,如张嘴、撅嘴等。
这位学员希望将来能成为一名心理咨询师,并表示能够通过面部表情传达情绪对她来说非常有价值。
尽管如此,使用头像的挑战在于它需要高保真,这样看起来才不会太不真实。当我们开始这个项目时,我们使用的是一个非常粗糙的头像,它不是很逼真,也没有舌头模型。作为神经工程师,我们需要一个高质量的头像,让我们能够接触到它的肌肉和声带系统。因此,找到一个好的平台至关重要。
您曾提到对控制面部表情的信号进行解码。您能再谈谈您是如何做到这一点的吗?

戈帕拉:这里有个比喻: 一首乐曲可以分解成若干个离散的音符,每个音符捕捉到的音高都截然不同。把凯洛提到的离散代码想象成这些音符。音符听起来像什么,与之相关的还有产生声音所需的条件。因此,如果音符是 “pa”,它听起来就像 “pa”,但同时也体现了嘴唇撅在一起然后松开的动作。
机制是由化身处理的这些单元编码的,而声音则是合成发生的地方。从本质上讲,我们是在将神经语音序列分解成离散的音符序列。
想象一下这个句子: “嘿 你好吗” 有一连串声带运动与这个声音相关。我们可以训练一个模型,将这些肌肉运动转换成离散的代码,类似于音乐中的音符。然后,我们可以从大脑中预测离散代码,并由此返回到连续的肌肉运动,这就是驱动化身的动力。
人工智能在这种新型脑机接口和多模态通信的开发过程中发挥了怎样的作用?
戈帕拉 所有的算法和为让你的 Alexa 工作而开发的东西,都是实现其中某些功能的关键。因此,广义地说,没有人工智能,我们就无法做到这一点。我所说的人工智能,指的不仅仅是目前的人工智能,比如 ChatGPT,而是实现了数十年人工智能和机器学习的核心工程。
更重要的是,我们在使用神经植入物访问大脑的范围方面仍然受到限制,因此我们的视野非常稀疏。我们基本上是通过一个钥匙孔在窥视,所以我们总是必须使用人工智能来填补缺失的细节。这就好比你可以给人工智能一张原始草图,它可以填补细节,使之更加逼真。
最终,当我们为假肢找到一个完全封闭的解决方案时,我们的目标是找到一个交流伙伴。这可能是一种人工智能,它可以利用从人身上感知到的任何信号,但也会像 ChatGPT 一样,利用大量统计数据来确定如何做出最佳回应,从而做出更符合上下文的回应。
有没有与你的工作相关的惊人发现?
凯洛 最重要的一点是,我们发现声道表征在参与者的大脑中得以保留。我们从对健康参与者的研究中得知,当一个人试图说话时,这些口腔运动会被编码到大脑皮层中。但目前还不清楚严重瘫痪者的情况是否如此。例如,这些区域是否会随着时间的推移而萎缩,还是说这些表征仍然存在,我们可以利用它们来解码语音?
我们证实,是的,发音或声道表征保留在参与者的大脑皮层中,而这正是这三种模式都能发挥作用的原因。
戈帕拉 没错!所以大脑部分仍然将这些代码保留在正确的位置。我们算是中了头奖。因为如果有损失,手术就白做了。而人工智能正在帮助我们填补这些细节。但它也有助于让参与者感受到自己的存在,并学习新的说话方式,而这正是进入下一阶段的关键所在。
也就是说,目前的人工智能是以计算机为中心,而不是以人类为中心。我们需要重新思考,当有人类参与时,人工智能应该是什么样子,让它更加以人为本,而不是各自为政。人工智能需要与人类共享自主权,这样人类仍然可以坐在驾驶座上,而人工智能则是合作的代理。
你认为下一步该怎么做?
凯洛 对于实际应用来说,拥有一个能长期工作的稳定解码器非常重要。如果我们能开发出一种参与者可以带回家并在数年内日常使用的解码器,而不需要再次进行神经外科手术,那将是最理想的。
戈帕拉 我认为,下一步的当务之急是缩短整个过程的延迟时间。因此,从参与者想到她想说的话到从化身口中说出这句话之间的几秒钟延迟,我们将把延迟降到最低,让她感觉整个过程是实时的。
我们还应该研究将假体小型化,使其成为一个独立的设备,就像心脏起搏器一样。它应该自己行动,自己供电,并始终与参与者在一起,而不是由研究人员来驱动仪器。
加州大学旧金山分校和伯克利工程公司之间的合作对这个项目的成功有何影响?
戈帕拉 这项研究大量使用了我们在伯克利开发的工具,而这些工具的灵感又来自加州大学旧金山分校的神经科学见解。这就是为什么 Kaylo 是工程、科学和医学之间的关键联系人–他既参与了这些工具的开发,又将其应用于临床。我认为,除了在工程和医学领域最顶尖、研究最前沿的地方,在其他任何地方都无法实现这一点。
Kaylo:如果没有伯克利大学和加州大学旧金山分校提供的所有资源,我想这个项目是不可能实现的。我们利用了工程学、人工智能以及我们对神经语音处理的理解等方面的最新进展,使这个项目得以顺利进行。这是两个机构携手合作,共同完成一项出色研究的典范。