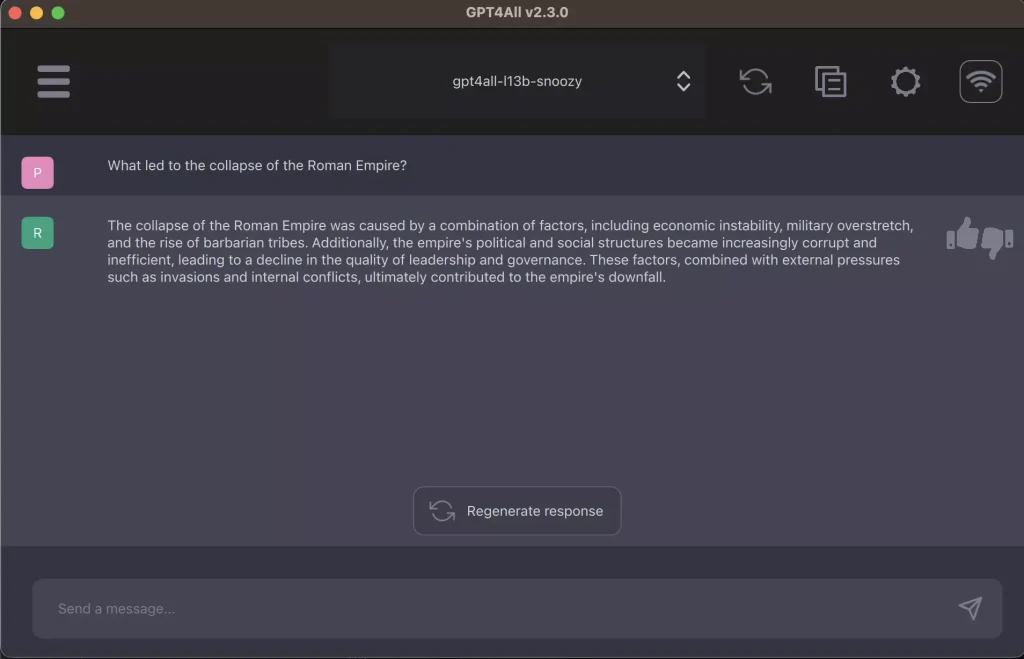
GPT4All
一个免费使用、本地运行、具有隐私意识的聊天机器人。无需 GPU 或互联网。

M1 Mac 上的实时推理延迟
下载桌面聊天客户端
1.Windows 版:【点击下载】
2.MacOS版:【点击下载】
3.Ubuntu版:【点击下载】
4.Github开源地址:【链接直达】
5.本地模型下载:【点击前往】
6.模型推荐:Mistral OpenOrca 【点击下载】或者软件内下载,在GPU的加速下,速度非常快!
GPT4All 的功能
探索 GPT4All 的功能。在您自己的硬件上。
回答有关世界的问题
有任何问题都可以向 GPT4All 询问。
个人写作助理
撰写电子邮件、文档、创意故事、诗歌、歌曲和戏剧。
了解文档
提供您自己的文本文档并接收有关其内容的摘要和答案。
编写代码
获取有关简单编码任务的指导。代码能力正在改进中。
模型下载:
大小:3.83 GB内存:8GB
密斯特拉尔-7b-openorca.Q4_0.gguf
最佳整体快速聊天模型
- 快速响应
- 基于聊天的模型
- 由 Mistral AI 训练
- 在通过Nomic Atlas管理的 OpenOrca 数据集上进行了微调
- 已获得商业用途许可
大小:3.83 GB内存:8GB
米斯特拉尔-7b-指令-v0.1.Q4_0.gguf
最佳整体快速指令跟随模型
- 快速响应
- 由 Mistral AI 训练
- 未经审查
- 已获得商业用途许可
大小:3.92 GB内存:8GB
gpt4all-falcon-q4_0.gguf
模型速度非常快,质量很好
- 最快的响应
- 基于指令
- 由TII培训
- 由 Nomic AI 微调
- 已获得商业用途许可
大小:3.56 GB内存:8GB
orca-2-7b.Q4_0.gguf
- 基于指令
- 由微软培训
- 不能用于商业用途
大小:6.86 GB内存:16GB
orca-2-13b.Q4_0.gguf
- 基于指令
- 由微软培训
- 不能用于商业用途
大小:6.86 GB内存:16GB
Wizardlm-13b-v1.2.Q4_0.gguf
最佳整体较大型号
- 基于指令
- 给出很长的回复
- 仅用 1k 高质量数据进行微调
- 微软和北京大学培训
- 不能用于商业用途
大小:6.86 GB内存:16GB
努斯-爱马仕-llama2-13b.Q4_0.gguf
非常好的模型
- 基于指令
- 给出很长的回应
- 包含 300,000 条未经审查的说明
- 由 Nous Research 培训
- 不能用于商业用途
大小:6.86 GB内存:16GB
gpt4all-13b-snoozy-q4_0.gguf
整体模型非常好
- 基于指令
- 基于与 Groovy 相同的数据集
- 比 Groovy 慢,但响应质量更高
- 由 Nomic AI 培训
- 不能用于商业用途
大小:3.54 GB内存:8GB
mpt-7b-聊天-合并-q4_0.gguf
模型不错,架构新颖
- 快速响应
- 基于聊天
- 由 Mosaic ML 训练
- 不能用于商业用途
大小:1.84 GB内存:4GB
虎鲸-mini-3b-gguf2-q4_0.gguf
具有新颖数据集的新模型的小版本
- 基于指令
- 解释调整后的数据集
- Orca 研究论文数据集构建方法
- 不能用于商业用途
大小:1.74 GB内存:4GB
重复代码-v1_5-3b-q4_0.gguf
在堆栈的子集上进行训练
- 基于代码完成
- 已获得商业用途许可
- 警告:不适用于聊天 GUI
大小:8.37 GB内存:4GB
starcoder-q4_0.gguf
在堆栈的子集上进行训练
- 基于代码完成
- 警告:不适用于聊天 GUI
大小:3.56 GB内存:8GB
裂痕编码器-v0-7b-q4_0.gguf
接受过 Python 和 TypeScript 集合培训
- 基于代码完成
- 警告:不适用于聊天 GUI
大小:0.04 GB内存:1 GB
全MiniLM-L6-v2-f16.gguf
LocalDocs 文本嵌入模型
- LocalDocs 功能所必需的
- 用于检索增强生成(RAG)
大小:3.83 GB内存:8GB
em_german_mistral_v01.Q4_0.gguf
基于 Mistral 的德语应用模型
- 快速响应
- 基于聊天的模型
- 由埃拉米德培训
- 对德语指令和聊天数据进行了微调
- 已获得商业用途许可
非特殊说明,本博所有文章均为博主原创。
如若转载,请注明出处:https://www.zerotech.cc/1112.html


防审查防追踪,安全又便捷!!")


